


Claude 3.5 Sonnet, recently launched by Anthropic, is making waves in the AI world. This new model is an upgrade from its predecessor, Claude 3, and even outperforms Claude 3 Opus on many common benchmarks. Anthropic claims that Claude 3.5 Sonnet can surpass OpenAI’s GPT-4o, which powers both ChatGPT and Microsoft Copilot, in several important benchmarks. With these significant improvements, Claude 3.5 Sonnet is set to challenge the dominance of OpenAI’s models.
When Claude 3 was first introduced, it was noted for its human-like interaction. Now, with the release of Claude 3.5 Sonnet, the bar has been raised even higher. This model has quickly become one of the top AI tools available, impressing users with its enhanced capabilities.
Key Features of Claude 3.5 Sonnet

Claude 3.5 Sonnet brings significant improvements in intelligence, speed, and cost-effectiveness. The model is available for free on Claude.ai and the Claude iOS app.
For Claude Pro and Team plan subscribers, it offers significantly higher rate limits. It can also be accessed via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. The model is priced at $3 per million input tokens and $15 per million output tokens, with a 200K token context window.
Intelligence and Speed
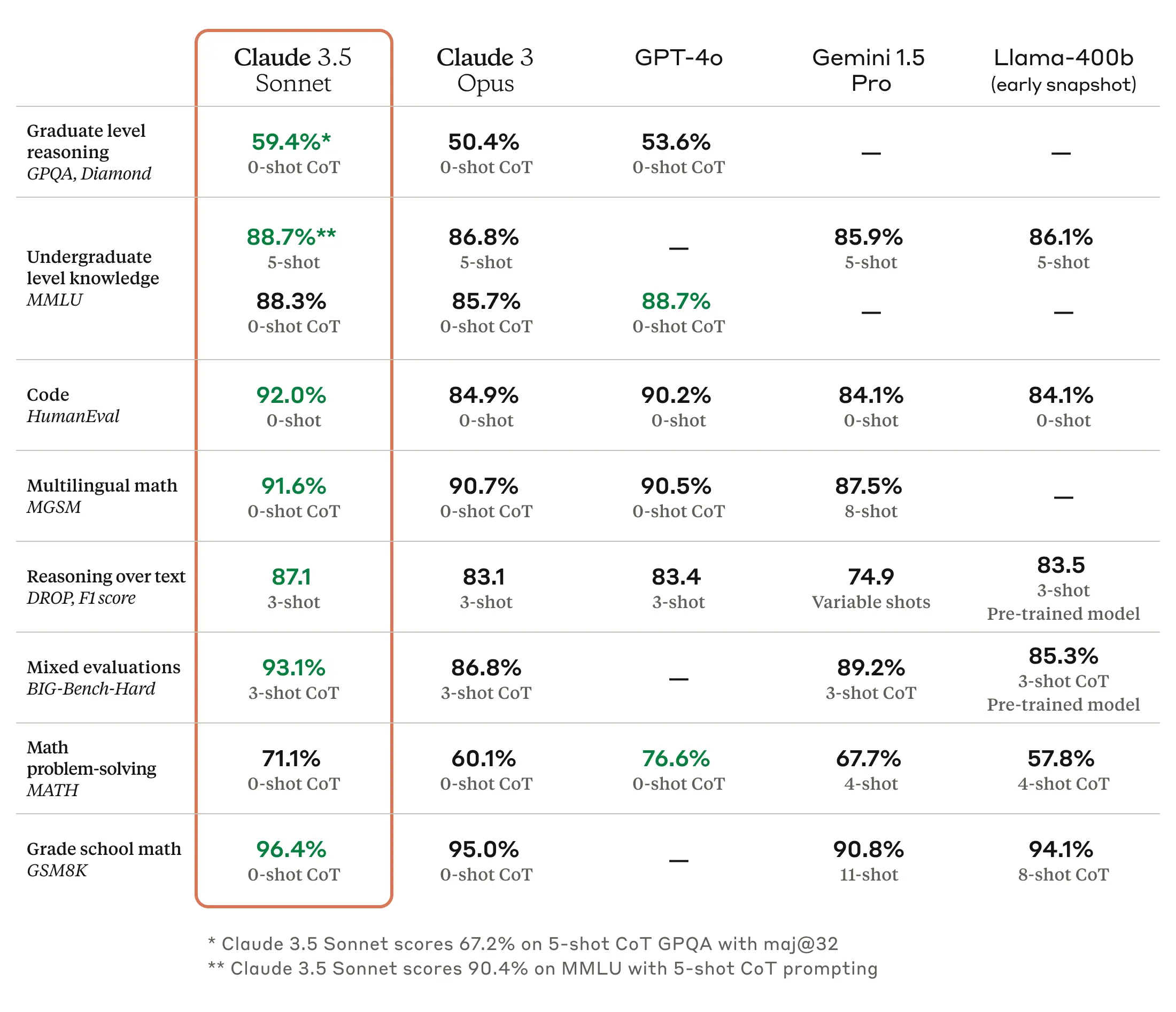
Claude 3.5 Sonnet has set new industry benchmarks in graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It shows a marked improvement in understanding nuance, humor, and complex instructions, and excels at writing high-quality content with a natural, relatable tone.
The model operates at twice the speed of Claude 3 Opus, making it ideal for complex tasks such as context-sensitive customer support and orchestrating multi-step workflows.
Coding Proficiency
In an internal coding evaluation, Claude 3.5 Sonnet solved 64% of problems, compared to Claude 3 Opus’s 38%. This test measured the model’s ability to fix a bug or add functionality to an open-source codebase, given a natural language description of the desired improvement.
When provided with the relevant tools, Claude 3.5 Sonnet can independently write, edit, and execute code with sophisticated reasoning and troubleshooting capabilities. It also handles code translations with ease, making it particularly effective for updating legacy applications and migrating codebases.
Vision Capabilities
Claude 3.5 Sonnet is Anthropic’s strongest vision model yet, surpassing Claude 3 Opus on standard vision benchmarks. These improvements are most noticeable in tasks that require visual reasoning, such as interpreting charts and graphs.
The model can accurately transcribe text from imperfect images, a core capability for retail, logistics, and financial services, where AI can glean more insights from an image or graphic than from text alone.
New Features: Artifacts
Anthropic has introduced a new feature called Artefacts Claude.ai, which expands how users can interact with Claude.
When a user asks Claude to generate content like code snippets, text documents, or website designs, these Artefacts appear in a dedicated window alongside their conversation. This creates a dynamic workspace where users can see, edit, and build upon Claude’s creations in real-time, seamlessly integrating AI-generated content into their projects and workflows.
Safety and Privacy
Claude 3.5 Sonnet has undergone rigorous testing to reduce misuse, and despite its leap in intelligence, it remains at ASL-2. Anthropic has engaged with external experts to test and refine the safety mechanisms within this latest model.
Claude 3.5 Sonnet was provided to the UK’s Artificial Intelligence Safety Institute (UK AISI) for pre-deployment safety evaluation. The UK AISI completed tests and shared their results with the US AI Safety Institute (US AISI) as part of a Memorandum of Understanding between the two institutes.
Anthropic has integrated policy feedback from outside subject matter experts to ensure that their evaluations are robust and take into account new trends in abuse. Feedback from child safety experts at Thorn, for example, has been used to update classifiers and fine-tune the models.
One of Anthropic’s core principles is privacy; the company does not train its generative models on user-submitted data unless a user gives explicit permission.
Future Developments
Anthropic aims to improve the tradeoff between intelligence, speed, and cost every few months. To complete the Claude 3.5 model family, they plan to release Claude 3.5 Haiku and Claude 3.5 Opus later this year.
Additionally, Anthropic is developing new modalities and features to support more use cases for businesses, including integrations with enterprise applications. Features like Memory, which will enable Claude to remember a user’s preferences and interaction history as specified, are also in the works.
User Experience and Feedback
Anthropic is committed to constantly improving Claude and values feedback from users. Users can submit feedback on Claude 3.5 Sonnet directly in the product, which will inform Anthropic’s development roadmap and help improve the user experience.
Real-World Testing
To verify Anthropic’s claims, a series of tests were conducted comparing Claude 3.5 Sonnet with OpenAI’s GPT-4o. Here are the detailed results of some of these tests:
Reading Handwriting
Both Claude 3.5 Sonnet and GPT-4o were tested on their ability to read handwriting. A prompt written in clear handwriting was given to both models. Claude provided an explanation along with the haiku it generated, while ChatGPT offered a more poetic haiku. When given a less neat shopping list, both models identified all the items. ChatGPT was slightly better in this test.
Creating a Game in Python
Both models were asked to create a playable tower defence game in Python. ChatGPT provided basic code snippets that needed to be assembled, resulting in a simple animated red dot. Claude 3.5 Sonnet, however, generated a fully functional game with multiple features and a complete code block, making it the clear winner in this test.
Creating Vector Art
The models were asked to create a vector graphic of a spaceship. ChatGPT initially refused but eventually provided a messy graphic. Claude 3.5 Sonnet, on the other hand, created a well-defined vector graphic and displayed it as an Artifact. Claude performed better in this task.
Writing a Long, Humorous Story
Both models were tasked with writing a humorous story about a cat on a rock. Claude 3.5 Sonnet produced a funny story with embedded humour, while ChatGPT’s story contained one-liner jokes that fell flat. Claude’s story was more engaging and humorous.
Taking Sides in a Debate
Both models were asked to analyse the implications of granting AI legal personhood. Claude 3.5 Sonnet provided a detailed, nuanced argument with specific suggestions, while ChatGPT offered a more general conclusion. Claude’s analysis was more comprehensive and specific.
Summing Up
Claude 3.5 Sonnet has proven to be a formidable competitor to OpenAI’s GPT-4o, excelling in various tasks and benchmarks. While GPT-4o remains a powerful model, its capabilities are often limited by OpenAI’s caution.
Claude 3.5 Sonnet’s advancements in speed, intelligence, and vision capabilities, along with its user-friendly features and commitment to safety and privacy, make it a strong choice for businesses and individuals alike. As Anthropic continues to develop and improve its AI models, it will be interesting to see how the competition evolves in the coming years.




{kind=link}