


A fundamental challenge of Natural Language Processing is the retrieval of relevant documents pertaining to a particular query and using them for the generation of paragraph length answer. Open-Domain Long-on answering Form poses a question towards this challenge.
In recent times, factoid open-domain question answering has witnessed significant progress, with the only requirement for answering a question being a short phrase. However, in the domain of long-form question answering, the level of efforts is comparatively less. LFQA holds significance primarily because it provides a testing ground for the measurement of the factuality of the text model. But the current metrics for evaluation are in need of more improvement in order to ensure LFQA progress.
Google.ai in a recent paper named “Hurdles to Progress in Long-Form Question Answering”, introduces a system for LFQA that effectively makes use of the advances in NLP, namely the state of the art sparse attention models and retrieval based models which addresses each of the challenges related to LFQA.
Text Generation
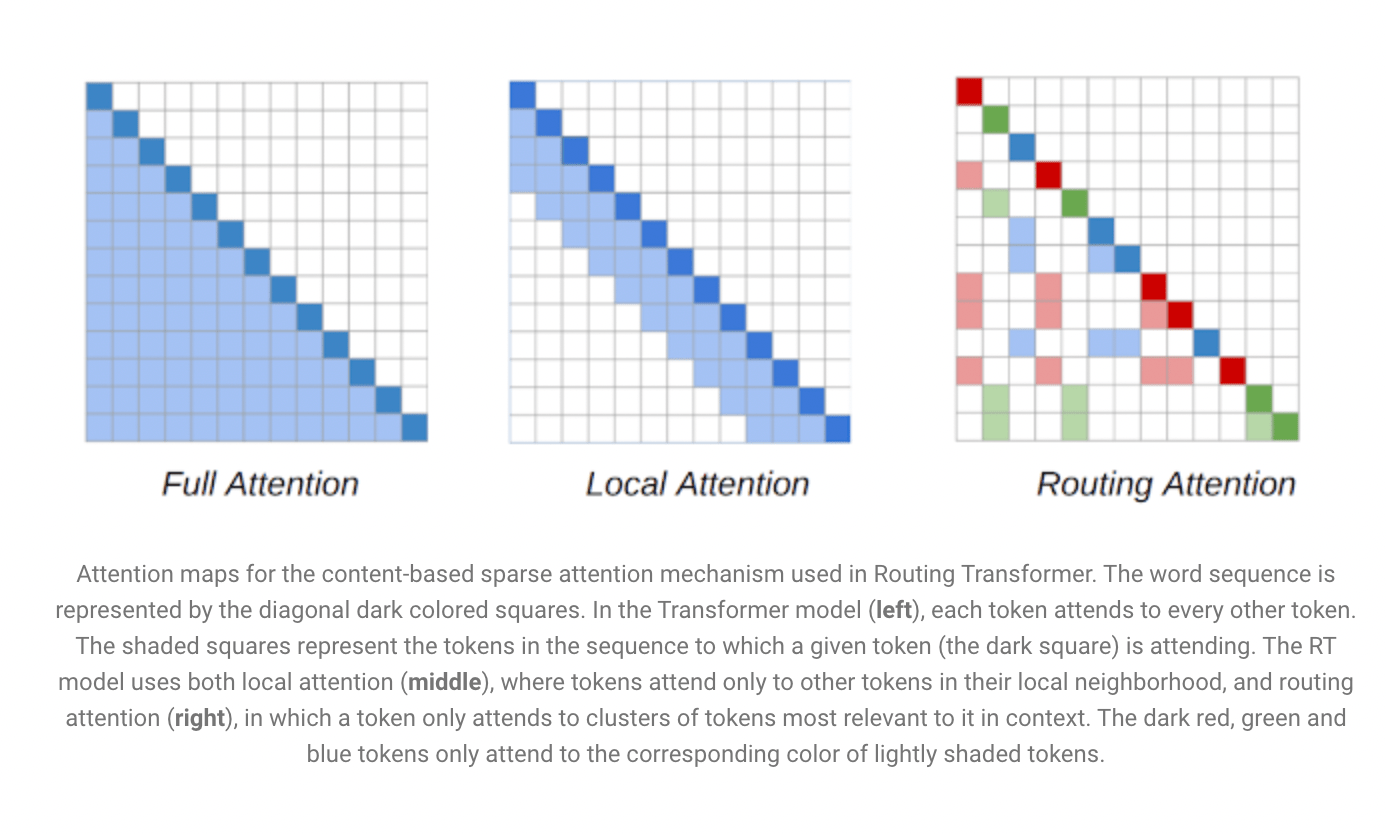
Transformer architecture is an important constituent of NLP models. The complexity in attention of the transformer model is considerably decreased by the RT model with the introduction of a dynamic mechanism completely based on content. The RT model is pre trained with a language modelling objective on the Project Guttenberg dataset.
Information Retrieval
The effectiveness of the RT model was showcased by the researchers when they combined it with retrievals from REALM. REALM is a retrieval based model that fetches Wikipedia articles pertaining to a particular query by maximum utilization of inner product search. With the backing of a contrastive loss, the quality of the REALM retrievals was boosted.
Evaluation
By using the ELI5 dataset, a test was run on the model with respect to long form question answering. ELI5 is a constituent of the KILT benchmark and it is also the only large scale LFQA dataset that is available to the public. After the tests, the pre trained RT models and retrievals from c-REALM was fine tuned on the dataset.
At present, the submission holds the first place on the KILT leaderboard. However, there are certain challenges associated with the model which has to be addressed. There was no solid evidence attesting the fact that the model’s next generation grounding is on the retrieved documents. Overlap in training, validation, and test sets of ELI5 was another significant issue, in addition to the blank spots in the Rogue-L metric, responsible for the evaluation of the quality of text generation.
It is expected that these challenges will be addressed and solved at the earliest, thereby making remarkable progress.



{kind=link}