


The field of natural language processing (NLP) has witnessed a paradigm shift in recent years with the advent of large language models (LLMs). These models have been shown to achieve remarkable performance on a wide range of NLP tasks, including text classification, sentiment analysis, language modeling, and machine translation, to name a few. However, the sheer size and complexity of these models make them computationally expensive and difficult to use in real-world applications. To address this challenge, the Hugging Face library provides a user-friendly interface for leveraging pre-trained LLMs to solve complex AI tasks. This report explores the concept of HuggingGPT, which is the use of Hugging Face models to harness the power of LLMs for solving complex AI tasks.
What is Hugging Face?
Hugging Face is an open-source library that provides a comprehensive set of tools for working with LLMs. The library is built on top of PyTorch and TensorFlow and provides pre-trained models for a wide range of NLP tasks. Hugging Face models can be used to solve a variety of AI tasks, including text classification, sentiment analysis, question-answering, and text generation, among others. In addition, the library provides a user-friendly interface for fine-tuning pre-trained models on custom datasets, making it easy to create models that are tailored to specific use cases.
The Hugging Face library is designed to be easy to use, even for those with limited experience in NLP. The library provides a simple and intuitive interface for loading pre-trained models, processing text data, and making predictions.
What are Large Language Models (LLMs)?
LLMs are deep learning models that are trained on massive amounts of text data. These models are typically pre-trained on large corpora of text using unsupervised learning techniques. The pre-training process involves training the model to predict missing words in a sentence, given the context of the surrounding words. This process is known as language modeling and is a fundamental task in NLP.
Once a model has been pre-trained on a large corpus of text, it can be fine-tuned on a specific NLP task using a small amount of labeled data. Fine-tuning involves training the model on a smaller dataset to improve its performance on a specific task. For example, a pre-trained language model could be fine-tuned on a sentiment analysis task by training it on a dataset of labeled movie reviews.
LLMs have achieved state-of-the-art performance on a wide range of NLP tasks, surpassing human-level performance on some benchmarks. However, the computational cost of training and using LLMs is significant. These models require massive amounts of compute and memory, and even pre-trained models can take hours or days to run on a single GPU.
Why Use Hugging Face Models?
Hugging Face is an open-source library for natural language processing (NLP) that provides pre-trained models for a wide range of NLP tasks. The library is built on top of PyTorch and TensorFlow, and it provides a simple and intuitive interface for working with these models. There are several reasons why Hugging Face models are popular among NLP practitioners:
- Pre-trained models: Hugging Face provides a wide range of pre-trained models for various NLP tasks, including text classification, sentiment analysis, named entity recognition, and more. These models have been trained on large datasets, and they achieve state-of-the-art performance on many benchmarks. Using pre-trained models can save a significant amount of time and effort in building an NLP application, as developers can leverage the knowledge and expertise that has gone into pre-training these models.
- Fine-tuning: Hugging Face models can be easily fine-tuned on a small dataset to achieve better performance on a specific task. This process involves training the pre-trained model on a small dataset that is specific to the task at hand, such as sentiment analysis of product reviews. Fine-tuning allows developers to tailor the pre-trained model to their specific use case, and it can result in significant improvements in accuracy.
- Transfer learning: Hugging Face models enable transfer learning, which is the ability to apply knowledge learned from one task to another related task. For example, a model pre-trained on a language modeling task can be fine-tuned on a text classification task, as the skills required for both tasks overlap to some extent. Transfer learning can reduce the amount of labeled data required for training a model, as the model can leverage knowledge learned from pre-training on a related task.
-

Credits: SabrePC User-friendly interface: Hugging Face provides a simple and intuitive interface for loading pre-trained models, processing text data, and making predictions. The library is designed to be easy to use, even for those with limited experience in NLP. The interface allows developers to quickly prototype and iterate on NLP applications, without having to spend significant time on model development and optimization.
- Community support: Hugging Face has a large and active community of developers and researchers who contribute to the library and provide support to users. The community provides a wealth of resources, including tutorials, code examples, and forums for discussion and collaboration. This support can be invaluable for developers who are new to NLP and want to learn best practices and get help with specific issues.
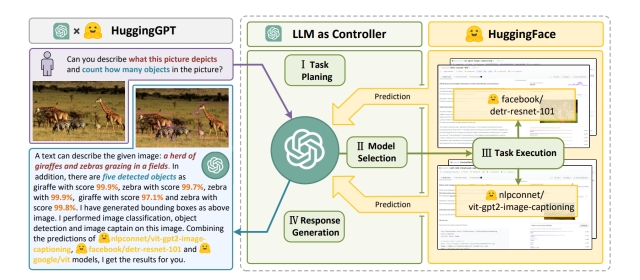
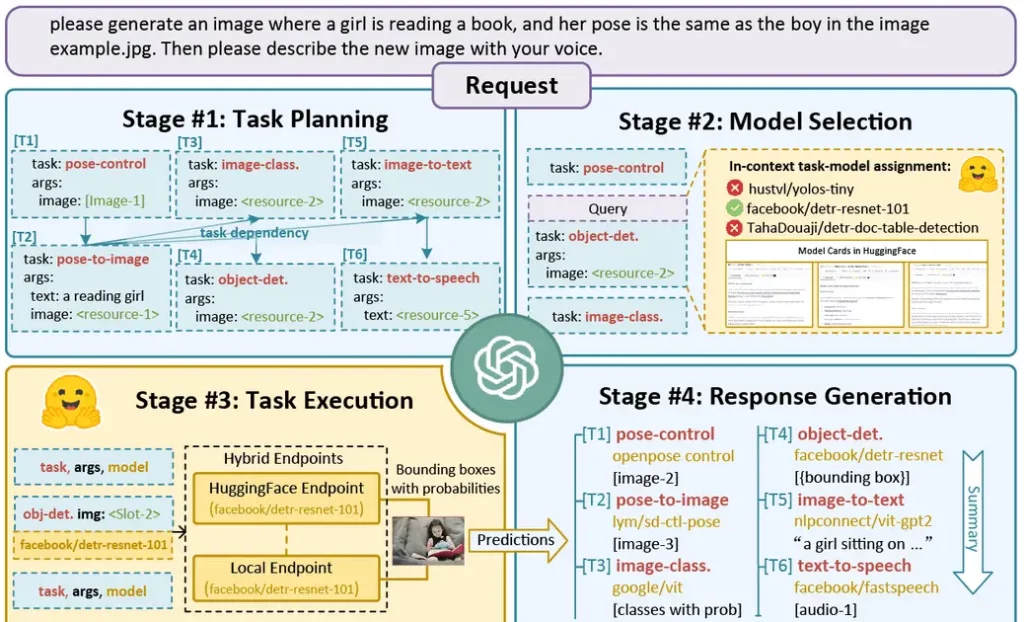
HuggingGPT
HuggingGPT is the use of Hugging Face models to leverage the power of large language models (LLMs. HuggingGPT has integrated hundreds of models on Hugging Face around ChatGPT, covering 24 tasks such as text classification, object detection, semantic segmentation, image generation, question answering, text-to-speech, and text-to-video. Experimental results demonstrate the capabilities of HuggingGPT in processing multimodal information and complicated AI tasks.
According to their creators, HuggingGPT still suffers from some limitations, including efficiency and latency, mostly related to the need of interacting at least once with a large language model for each stage; context-length limitation, related to the maximum number of tokens an LLM can accept; and system stability, which can be reduced by the possibility an LLM occasionally failing to conform to instructions, as well as by the possibility that one of the models controlled by the LLM may fail.
Several advantages to using HuggingGPT for solving complex AI tasks:
- State-of-the-art performance: It is one of the most powerful LLMs available today, and it has achieved state-of-the-art performance on many NLP benchmarks. Fine-tuning on a specific task can result in performance that is on par with or better than existing state-of-the-art models. This makes HuggingGPT a powerful tool for solving complex AI tasks that require advanced NLP capabilities.
- Reduced data requirements: It can reduce the amount of labeled data required for training a model. This is because the model has already been pre-trained on a massive amount of text data, and it has learned to recognize patterns and relationships in language that are relevant to many NLP tasks. This means that it can be fine-tuned on a smaller dataset than would be required to train a model from scratch. This can significantly reduce the time and cost required to train a model, as well as the amount of labeled data that is required.
-
Credits: Easy withAI Customizability: It allows developers to tailor the model to their specific use case. This means that the model can be optimized for specific domains, such as legal or medical NLP, or for specific tasks, such as summarization or question answering. Fine-tuning also allows developers to incorporate domain-specific knowledge into the model, which can improve its performance on tasks that require domain-specific expertise.
- Adaptability: It is a highly adaptable model, which means that it can be fine-tuned on a wide range of tasks. This makes it a versatile tool for solving complex AI tasks that require advanced NLP capabilities. For example, it can be fine-tuned for chatbots, language translation, text summarization, and more. This adaptability makes it possible to solve complex AI tasks with a single model, rather than having to build and train multiple models for different tasks.
- Interpretability: HuggingGPT models are highly interpretable, which means that developers can understand how the model is making predictions. This is important for many applications, such as legal or medical NLP, where it is important to understand how the model is making decisions. The interpretability of HuggingGPT models also makes it easier to debug and optimize the model, as developers can see how the model is processing text data.
- Open-source: HuggingGPT is built on top of open-source technologies, which means that it is accessible to a wide range of developers and researchers. This openness makes it possible for developers to contribute to the library, improve the performance of the models, and customize the models for their specific use case. The open-source nature of HuggingGPT also means that developers can use the models without incurring licensing fees or other costs.
- Integration with other tools: HuggingGPT models can be easily integrated with other tools and platforms, such as web applications or chatbots. This means that developers can build complex AI applications that incorporate advanced NLP capabilities without having to spend significant time on model development and optimization. The integration of HuggingGPT with other tools also makes it possible to leverage existing infrastructure and data sources, which can save time and reduce costs.
- Scalability: HuggingGPT models can be deployed at scale using cloud computing services, such as Amazon Web Services or Google Cloud Platform. This means that the models can handle large volumes of text data and can be used in production environments. The scalability of HuggingGPT models makes it possible to build AI applications that can process large volumes of text data in real-time, such as chatbots or social media analysis tools.




{kind=link}