


OpenAI has introduced CriticGPT, a new AI model that can identify mistakes in code generated by ChatGPT. This development is significant as it aims to improve the accuracy of AI-generated outputs.
Built using OpenAI’s flagship AI model, GPT-4, CriticGPT helps human reviewers spot errors and bugs in code, enhancing the alignment of AI systems through a method called Reinforcement Learning from Human Feedback (RLHF).
CriticGPT is designed to assist in the evaluation of AI-generated code by identifying mistakes and highlighting inaccuracies. The primary goal of this tool is to support human AI reviewers in their work, making the process of spotting errors more efficient and accurate.
The researchers behind CriticGPT trained the model using a dataset of code samples with deliberately inserted bugs. This training approach enabled CriticGPT to recognize and flag coding errors effectively.
One of the notable features of CriticGPT is its ability to write detailed critiques of ChatGPT’s responses. These critiques help human trainers identify and correct mistakes during the RLHF process. This method of training AI systems involves collecting feedback from humans who rate different AI responses against each other, ensuring that the AI becomes more accurate over time.
By providing comprehensive critiques, CriticGPT helps improve the overall quality of AI-generated code.
Training and Capabilities of CriticGPT
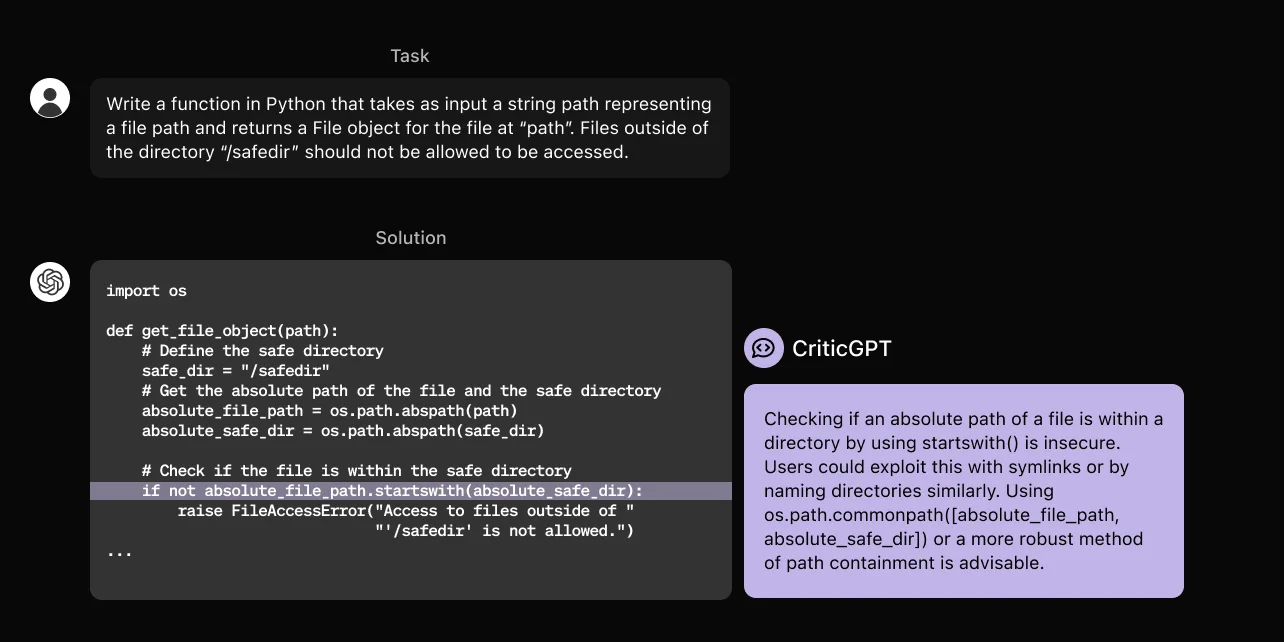
CriticGPT’s training process involved exposing the model to a large number of inputs containing intentional mistakes. AI trainers manually inserted these bugs into code written by ChatGPT and then provided example feedback as if they had discovered the errors. This approach ensured that CriticGPT learned to identify and critique these bugs accurately.
Additionally, CriticGPT was evaluated on its ability to catch both inserted bugs and naturally occurring errors in ChatGPT’s code.
The research paper titled “LLM Critics Help Catch LLM Bugs” demonstrated CriticGPT’s competency in analyzing code and identifying errors. According to the study, the notes provided by CriticGPT were preferred by annotators over human notes in 63 percent of cases involving AI errors.
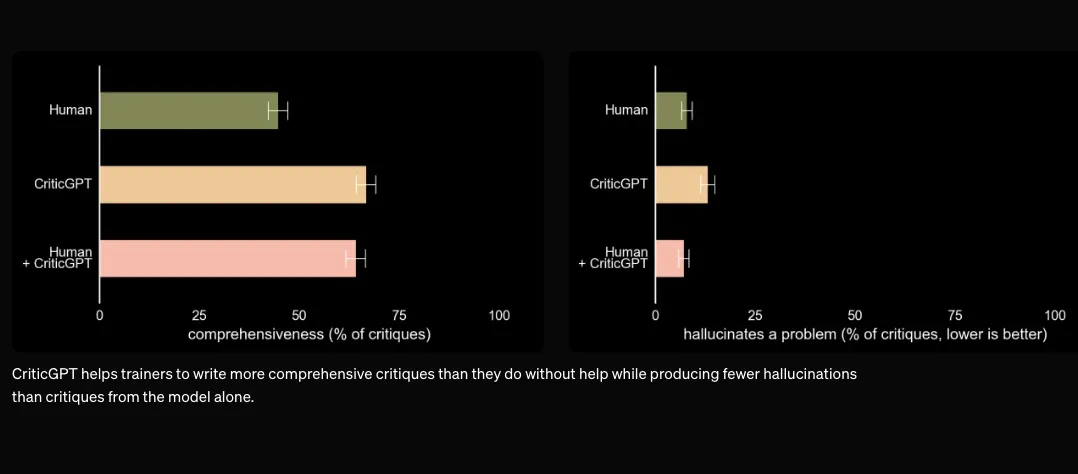
A unique feature of CriticGPT is its use of a technique called “Force Sampling Beam Search.” This technique allows users to adjust the thoroughness of the tool when looking for bugs, providing more control over its tendency to hallucinate or highlight non-existent errors. This adaptability makes CriticGPT a valuable tool for various coding tasks, although it does have some limitations when it comes to evaluating longer and more complex tasks.
Benefits and Limitations of CriticGPT
One of the significant benefits of CriticGPT is its ability to enhance the performance of human reviewers. Studies have shown that when people use CriticGPT to review ChatGPT’s code, they outperform those who do not have access to the tool 60 percent of the time. This improvement is crucial as it helps AI trainers provide more accurate and detailed feedback, ultimately leading to better-trained AI models.
CriticGPT’s suggestions are not always correct, but they help trainers catch more problems with AI-generated code than they would without AI assistance. When human reviewers use CriticGPT, their critiques are more comprehensive and contain fewer hallucinated bugs than when working alone. In experiments, a second random trainer preferred critiques from the Human+CriticGPT team over those from an unassisted person more than 60 percent of the time.
Despite its advantages, CriticGPT has some limitations. The model was trained on relatively short responses from ChatGPT, which means it might struggle with longer and more complex tasks. T
o supervise the agents of the future effectively, methods need to be developed to help trainers understand and evaluate extensive and intricate tasks. Additionally, real-world mistakes in coding can be spread across multiple parts of an answer, making it challenging for CriticGPT to identify the source of the problem.

Future Prospects and Ongoing Research
The introduction of CriticGPT marks a significant step towards improving the accuracy and reliability of AI-generated code. OpenAI is working on integrating CriticGPT-like models into their RLHF labeling pipeline, providing trainers with explicit AI assistance. This integration aims to make the evaluation of outputs from advanced AI systems more manageable, especially as these models become more knowledgeable and their mistakes more subtle.
Ongoing research focuses on enhancing CriticGPT’s capabilities to handle longer and more complex tasks. The researchers acknowledge that models still hallucinate and that trainers can make labeling mistakes after seeing these hallucinations. Therefore, future work will address these challenges by developing methods to tackle dispersed errors and improve the overall performance of AI-generated critiques.




{kind=link}