


The frontier of Information Technology is no longer defined by the ability to aggregate data, but by the computational efficiency used to extract its value. In the high-velocity sectors of food-tech and digital content, the “accuracy at any cost” model has reached a breaking point. My career has been dedicated to resolving this crisis: architecting discovery engines that achieve hyper-relevance through fiscal and technical optimization.
From restructuring localized frameworks for corporate clients to engineering the logistics backbone for 300,000+ real-time delivery partners at Swiggy, I have spearheaded the migration from static logic to autonomous, budget-aware ML architectures. True innovation in today’s IT stack requires more than just better algorithms; it demands a paradigm shift in scaling—where segmentation and resource-allocation strategies are baked into the code to ensure that personalized discovery remains both a technical triumph and a sustainable business asset.
Understanding the Recommender System Landscape
A recommender system consists of several interlocking pieces that work together to deliver personalized experiences. Although the precise architecture varies based on the use case and scale requirements, the problem at its core is always the same: how do you match the right content, product, or opportunity with the right user at the right time?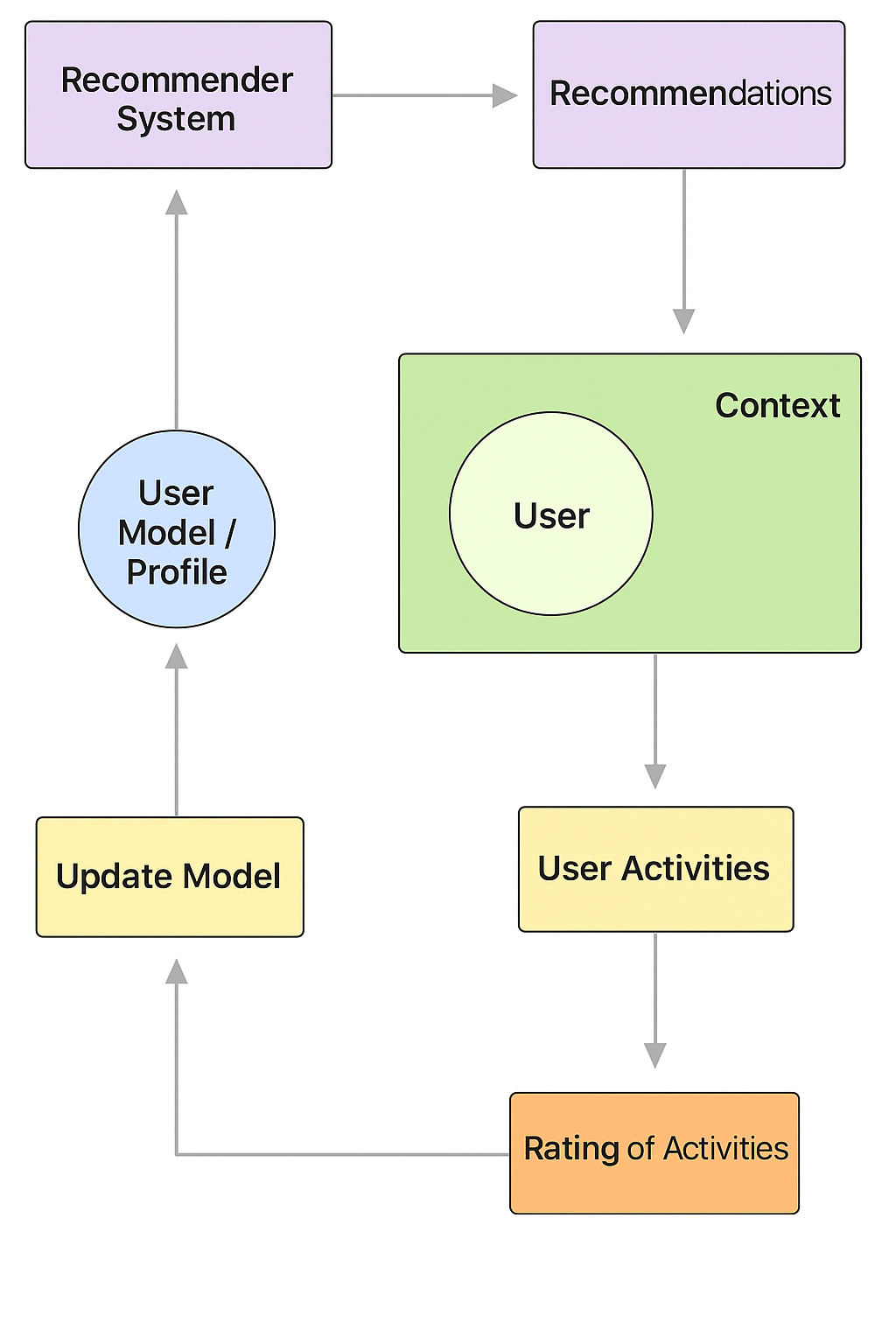 From my experience, here are five underlying techniques that form the basis of most recommendation systems. The simplest approach is popularity-based recommendations that surface the most popular, watched, or purchased items for users. It’s straightforward but effective and provides an excellent baseline that works particularly well for new users where behavioral data is limited. I’ve implemented this approach to provide useful “Top 10 near you” functionality that receives a high level of user interaction with minimal computational overhead.
From my experience, here are five underlying techniques that form the basis of most recommendation systems. The simplest approach is popularity-based recommendations that surface the most popular, watched, or purchased items for users. It’s straightforward but effective and provides an excellent baseline that works particularly well for new users where behavioral data is limited. I’ve implemented this approach to provide useful “Top 10 near you” functionality that receives a high level of user interaction with minimal computational overhead.
Content-based filtering is more elegant in that it recommends items that are similar to what a user has consumed in the past, using item metadata and attributes. It excels in situations where item attributes are dense and well-annotated. In my project with Frutta, a corporate refreshment company, content-based filtering was used to recommend complementary menu items based on nutritional profiles and dietary restrictions.
Collaborative filtering is a paradigm shift because it focuses on patterns in user behavior rather than item attributes. This “users like you also viewed” approach is based on the wisdom of the crowd, discovering users with similar tastes and cross-pollinating their interests. I witnessed the power of collaborative filtering when I was developing content discovery systems, where users with similar reading patterns could surface wonderful content that pure content-based approaches would miss.
Hybrid models combine multiple approaches to overcome individual limitations and reinforce strengths. In my practice of building large platforms like Swiggy and daily.dev, hybrid architectures were essential to cater to diverse user segments and use cases within the same system. These models can beautifully combine popularity signals for new users, content similarity for niche tastes, and collaborative patterns for exploration.
Two-tower deep models represent the state of the art in recommendation technology, where disjoint user and item representations are learned that can be efficiently matched using similarity calculations in embedding space. This is now my go-to solution for content-rich platforms where both scalability and personalization are important.
Case Study: Constraint-Aware Recommendations at Frutta
One of the most challenging recommendation problems I tackled was at Frutta, a fast-growing corporate refreshment brand that serves over 300 customers in three Indian cities. The challenge wasn’t just in matching preferences, it was in balancing multiple constraints simultaneously while optimizing at scale.
The problem was dual. No menu item should repeat too soon for the same customer, creating a diversity constraint not typically handled by traditional recommendation systems. Budget constraints varied extensively by client and needed to be filtered dynamically on a per-head cost basis. Geographic restrictions meant that not all kitchens could deliver to all places, and complex routing logic had to be involved. Client-specific dietary restrictions like vegan, low-carb, and Jain food requirements needed to be respected without compromising on variety or budget optimization.
We built a constraint-aware recommender engine that transformed our operation planning process. The most important innovation involved leveraging a diversity matrix that tracked menu item frequency by client and time interval to ensure optimal rotation while respecting preferences. Budget alignment also became dynamic, with the system filtering the options in real-time based on client spend parameters and portion size optimization.
Zone restrictions were tackled with innate routing intelligence that considered kitchen capacity, delivery logistics, and client location grouping. Rather than treating geography as an afterthought, we put it at the forefront of the recommendation algorithm. Client preference tags were given the status of hard filters, such that dietary restrictions were never compromised in the name of variety or cost optimization.
The result was revolutionary. The planning time per client dropped from 45 minutes of manual coordination to 3 seconds of computer processing. This efficiency gain allowed us to triple into three cities and surpass $1 million in annual revenue without a drop in service quality. Most importantly, perhaps, complaints resulting from repetition dropped to near zero, demonstrating that systematic constraint handling could solve operational problems that were apparently intractable by manual means.
Scaling Content Discovery with Two-Tower Architecture
At daily.dev, a platform that aggregates developer content and news from across the web, getting the right content in front of the right user isn’t a feature, it’s the entire value proposition. To personalize discovery at scale for a rapidly growing community of developers, we implemented a Two-Tower neural network architecture that could handle both the volume and velocity demands of content recommendation.
The Two-Tower model is apt at learning from both content features and user behavior at the same time and is apt for environments where both users and content are dynamic. One tower takes in user-specific input like browsing history, saved articles, frequency of interaction, and reading time patterns. The other parallel tower takes in content metadata like title embeddings, source reputation scores, topic classifications, and tag hierarchies.
These parallel embeddings are joined by similarity functions that are able to score and rank content relevance effectively in real-time. The elegance of this architecture is that it is able to precompute embeddings for millions of articles and compare them against dynamic user profiles in real-time. This division of concerns allows for both batch processing of content features and real-time customization of user experiences.
The system’s hybrid cold-start mechanisms were particularly valuable in handling new users and anonymous sessions. By taking advantage of content popularity cues and category-level preferences, we could make sensible recommendations even without a lot of user history. As the users engage more with the platform, the system seamlessly transitions from popularity-based suggestions to truly personalized recommendations using learned preferences.
The outcomes of the deployment validated our architectural choice. We saw significant improvement in content consumption metrics like click-through rates, scroll depth, and return frequency. More importantly, the system maintained low latency even as our user base and content corpus grew, proving that thoughtful architecture decisions made early in development pay dividends at scale.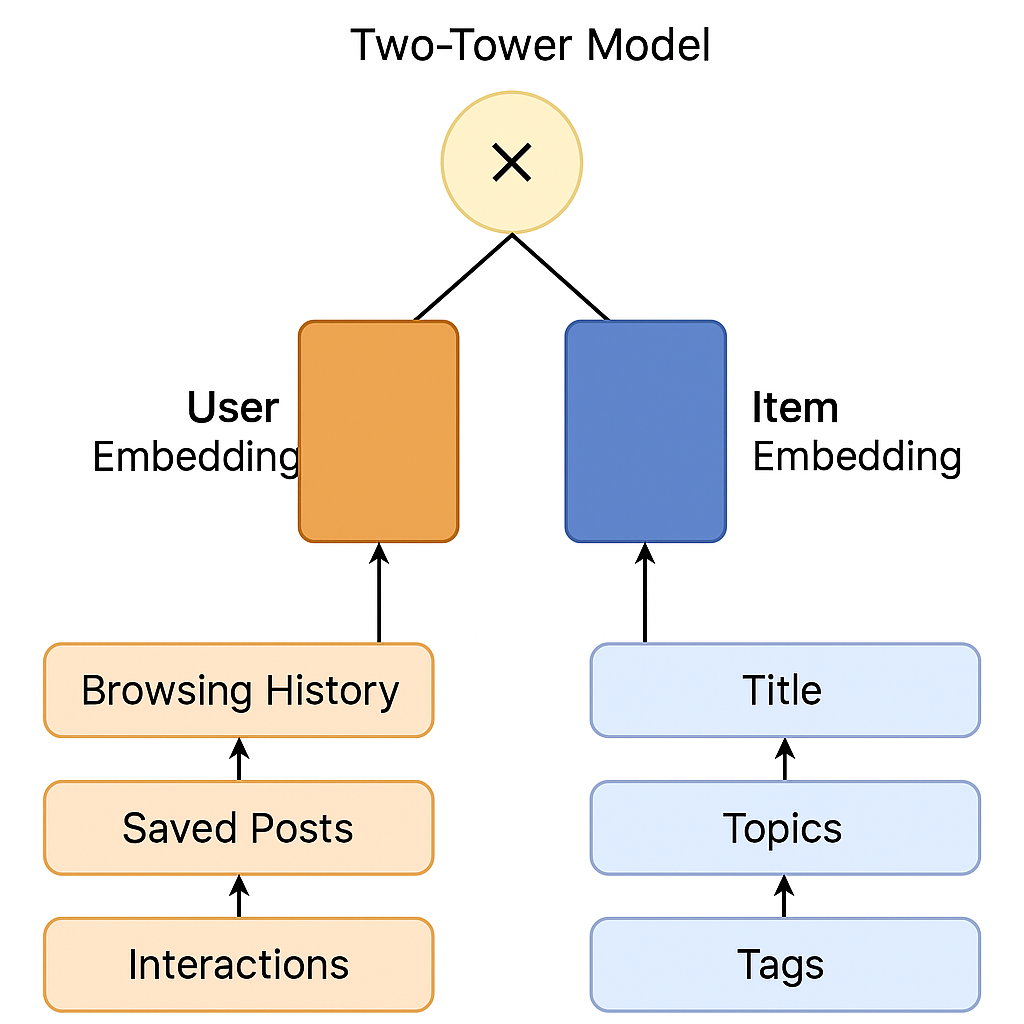
Managing Scale Challenges at 300K+ Users
The transition from managing hundreds of users to managing recommendations for over 300,000 delivery partners at Swiggy taught me important lessons on the unseen costs and nuances in scaling recommendation systems. What works wonderfully for thousands of users can become prohibitively expensive and operationally complex when scaled by orders of magnitude.
Early in our scaling, we approached personalization with the attitude that every user interaction deserved real-time processing and individually calculated recommendations. This worked well for us at first, as we delivered very personalized experiences that led to high engagement metrics. As our user base expanded rapidly, however, the infrastructure costs began to consume an unsustainable portion of our budget.
The reality check came when we calculated the true cost per recommendation across our entire user base. Real-time machine learning inference for hundreds of thousands of users, with multiple recommendation requests per day per user, made computational demands scale faster than revenue. The resource demands of sub-second response times while holding recommendation quality levels started eating budgets that were intended for other critical growth initiatives.
Performance versus cost trade-offs became a daily concern rather than a theoretical problem. We discovered that high performance was not merely algorithmic optimization but required rethinking from scratch when, how, and for whom we recommend. The issue was not purely technical but strategic and forced us to compromise on user experience quality and operational viability.
Budget Optimization Strategies That Actually Work
Through trial and error, we developed three underlying strategies that dramatically improved our cost efficiency without compromising recommendation quality. Our initial breakthrough was the application of smart sampling and batching strategies that challenged our assumptions about real-time processing requirements.
Not every user interaction needs real-time, uniquely computed recommendations. By examining user behavioral patterns, we identified that certain types of interactions could be batched and executed during off-peak hours without impacting user experience. For example, delivery partners who worked fixed shifts could receive optimized route and incentive recommendations as part of their usual pre-shift preparation time rather than on-demand.
We implemented intelligent sampling that processed a strategically selected subset of the user interactions in real-time and batched others for later processing. This lowered server loads by approximately 60% during peak hours while maintaining recommendation relevance for time-sensitive decisions. The insight here was to realize that different types of recommendations have different latency tolerance levels.
Our second major optimization was the construction of hybrid model architectures that combined rule-based logic and machine learning algorithms. Rather than framing these approaches as competing exclusives, we constructed systems that employed rule-based filters to efficiently process common cases, reserving computationally expensive machine learning inference for challenging edge cases and high-value users.
This hybrid approach particularly worked well for Swiggy’s delivery partner segments, which were heterogeneous. New partners were served recommendations with predefined rule-based logic at low computation cost, whereas older partners with rich behavioral histories were served by highly involved machine learning models. The system could adapt dynamically to both available data and computation budget, rendering the system cost-optimal without causing a stratified user experience.
Caching and precomputation was our third pillar of cost optimization, though caching for recommendation systems is less straightforward than for a standard web app. We observed that there were patterns in recommendations that were retrieved often, such as popular routes for specific time intervals and common incentive models for different partner segments.
Rather than recomputing such recommendations on every request, we precomputed popular requests during off-peak hours and served cached answers where possible. The problem was to maintain cache freshness while respecting personalization constraints. We did this by employing smart cache invalidation based on behavioral triggers and time-based refresh cycles that balanced cost savings against recommendation precision.
Lessons from Real-World Performance Optimization
The shift in our system performance metrics said more about the triumph of optimization than any formulaic model ever would. Before we began our optimization strategies, cost per recommendation was eating into our unit economics in ways that would have prohibited long-term scalability. By implementing intelligent sampling, hybrid architectures, and smart caching, we achieved substantial cost savings while actually improving some aspects of user experience.
System latency improvements were particularly strong in high-demand situations. Precomputation and caching strategies reduced response times for common queries by over 70%, creating discernibly more responsive user experiences during peak usage levels. More importantly, the reduced computational load allowed us to allocate resources to increasing recommendation quality for difficult scenarios rather than simply providing baseline performance.
The effect on user engagement validated our optimization approach. At Swiggy, better recommendations led to better retention and engagement for delivery partners, with measurable improvements in shift fulfillment rates and partner satisfaction scores. At daily.dev, optimization led to higher content interaction rates and overall platform growth, proving that performance optimization and user experience enhancements could be synergistic rather than competing objectives.
Strategic Takeaways for Product Leaders
Building large-scale recommendation systems requires thinking beyond algorithmic precision to the entire ecosystem of constraints, costs, and capabilities. Budgeting for recommendation systems must consider non-linear scaling phenomena where computational costs can grow faster than user bases or revenues. Starting with simple, low-cost solutions and developing based on actual usage patterns is more feasible than over-designing complex systems too soon.
The build versus buy versus hybrid decision framework takes center stage as recommendation systems mature. My experience has shown that hybrid solutions often provide the most ideal results, allowing teams to build core differentiated function while leveraging specialized services and tools for commodity capability. The trick lies in deciding what pieces provide competitive value and what can be successfully outsourced or purchased.
Organization of teams and skill sets required for effective recommendation systems extend outside of data science and engineering. As systems expand, cross-functional coordination across data science, engineering, product management, and operations is required. Each discipline provides various insights into user needs, technical feasibility, and business objectives that must be traded off in system design decisions.
The most important thing I wish I knew earlier is fighting the temptation to over-engineer solutions before understanding actual scale requirements and user behavior patterns. It is better to scale gradually and optimize against actual constraints rather than theoretical ones. Complex systems are easier to build than to run and maintain, and operational complexity tends to be the bottleneck to long-term success rather than algorithmic complexity.
Building recommendation systems that truly scale is a matter of balancing a number of competing requirements without losing focus on the end goal of matching users with value. The best systems I’ve built did that by bringing technical architecture and business concerns into balance in a way that created sustainable platforms for long-term growth and user satisfaction.




{kind=link}