


Image Credits: SimonPointer
Google Tag Manager is a TMS (Tag Management System) that enables marketing teams to add trackers to a website or application without the need for coders. These teams can make the following decisions using a web interface:
- To really be generated traces (analytics, A/B testing, attribution, and so forth).
- Conditions that set off the alarm (categories of pages, user characteristics, etc.).
- Content to be provided to these third-party applications (user characteristics, navigation data, variables present on the page, etc.).
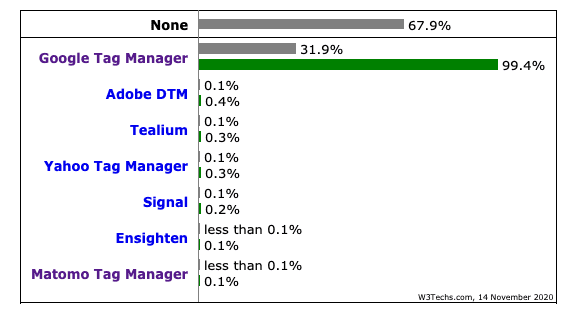
Image Credits: Woolyss
That isn’t the only one (others include Segment, TagCommander in France, & Matomo Tag Manager), but Google Tag Manager is by far the most popular: According to W3Techs, Google Tag Manager has been used on 31.9 percent of the top 10 million Alexa websites, but it also has a 99.4 percent of the global on TMS (!).
How has Google been able to re-establish its dominance? The basic version of Google Tag Manager, like Google Analytics, is free (market alternatives are usually charged), it is well connected with other Google products, and it is nicely done.
Trackers that aren’t being called by your browser any longer
Google released Server-Side Tagging, a new version of Google Tag Manager, in August. Here’s a figure from Google that explains how Client-Side Tagging (the “historical” version) of Google Tag Manager works:
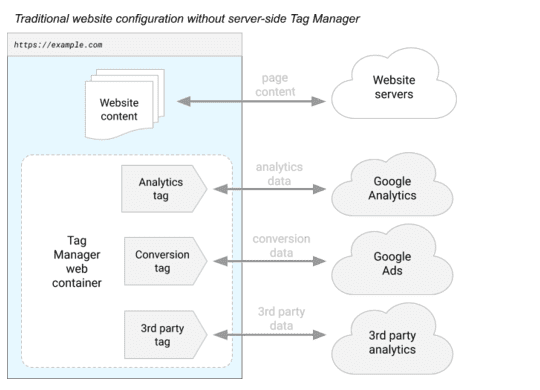
Image Credits: Woolyss
Google Tag Manager shall enable users to use your browsers to activate several third-party tracers (on the diagram: Google Analytics, Google Ads, and an analytics tool).
Third-party trackers were already operated from a ” Proxy ” server named “Server container” on the diagram below (and hosted by Google) rather than from your browser in the new Server-Side version:
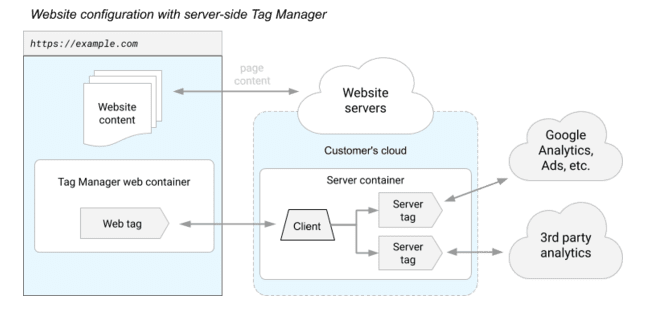
Image Credits: Woolyss
The javascript framework (referred to as “Tag Manager webserver” in the illustration) is constantly running on your browser to capture your activities & personal data, but the different third-party tracers are executed on the server. It’s worth noting that this updated version also applies to applications and “offline” data collecting (for instance, transmitting in-store purchases):
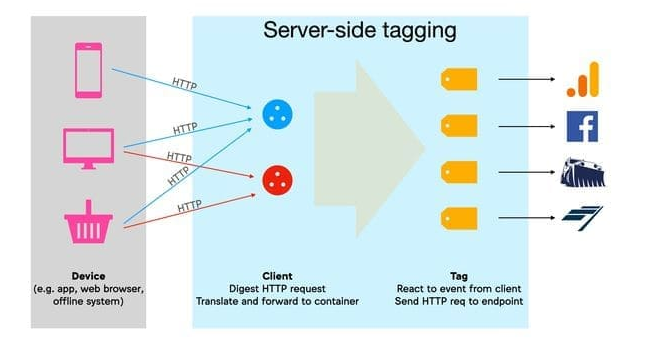
Image Credits: Woolyss
Simo Ahava’s blog diagram: mostly on server-side, “Clients” transform HTTP requests become “events,” and “Tags” respond to all of these happenings by sending “hits” to third-party marketing organizations.
The server-side mechanism for triggering third-party tracers is revolutionary. Simo Ahava has written an excellent post about the numerous implications; for my part, we’ll look at the positives as well as the confidentiality issues.
Enhance User Experience
The quantity of javascript libraries loaded by third parties (for analytics, advertising, A/B testing, and so on) is astonishing on most websites. The major reason of a poor user experience is the loading and functioning of these libraries: site slowness and lack of engagement.
Implications for websites that provide a poor user experience include less happy Internet users who will leave their surfing or never return. Here’s an example using Le Bon Coin, which uses a plethora of javascript libraries:
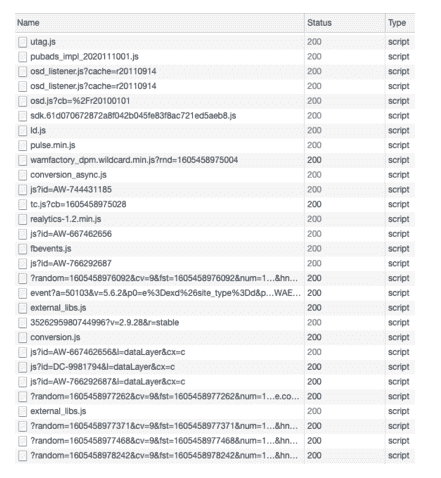
Image Credits: Woolyss
This is a minor section of the javascript scripts called on the Le Bon Coin home page that exposes your personal data to a variety of third parties. The website will only install one javascript library in the best case scenario (events can be very different between tools that do not have the same purposes, the website will sometimes use more than a single library).
This might be Google Tag Manager, but it is not required: you can design your own library or use one of the many available on the market, such as Snowplow, Matomo, AT Internet, and so on.
The library is then told to send the “hits” with the parameters needed for key interactions. The server container’s “client” will then have to convert these “hits” into events, which will be read by the “Tags,” which will then transmit “hits” to third-party marketing organizations.
The “client” is already pre-configured in Google Tag Manager if the javascript library used on the site is given by Google. If the website utilizes a different library, it will need to build its own “client” in Google Tag Manager (for example, AT Internet), while waiting for the main javascript tracking libraries to have “clients” pre-configured. As a result, with only one javascript tracking library installed on the website and only one “flow” of data from the browser, the user should notice a difference.
Improved control over data sent to other parties
Controlling the data sent to third parties is significantly easier using a “proxy” on the server-side (which is much more difficult when trackers are directly performed by the user’s browser):
The IP address and User-Agent (browser name, version, operating system, language, etc.) of the user are not leaked by definition, unlike with the “client-side” version (which avoids user identification via ” fingerprinting “). The publication that uses Google Tag Manager’s Server-Side Tagging version may choose to share this data with third parties, but that’s not automated.
Personal information is commonly transmitted to third-party companies via URL arguments (see, for example, ” Google Tag Manager Server-Side – How To Manage Custom Vendor Tags “), but Server-Side Tagging prevents this.
In general, the publisher retains control over the personal data and cookies transferred to third parties through its “proxy” (see Google’s technical information for further information, especially the get cookies & set cookies procedures). As a result, it may “clean” the data and only communicate what is really essential to third parties.
In the case of an AT Internet hit detected by the “proxy” server, the website may choose not to provide the user’s IP address and User-Agent to AT Internet.
Image Credits: Woolyss
Bypass to adblockers

Image Credits: Woolyss
Your adblocker (for example, uBlock Origin on Firefox), content blocker (for example, Firefox Focus or Adguard on iOS), and DNS blocker (for example, NextDNS) are all functional on your device. As a result, it can detect and prevent third-party trackers before your personal information is exposed.
With the Server-Side Tagging version of Google Tag Manager, none of this happens: personal data is leaked to third parties from the client’s proxy server (located in the Google cloud). You don’t have the ability to prevent these leaks anymore.
You can think to yourself, “Just block the first call, the one from your browser to the javascript library that collects data and communicates with the “proxy” server.” Except that this javascript library might very well be found on the web site’s domain (and not on a Google domain for example).
In addition, Google has previously advised its customers to update their gtag.js scripts to include the proxy server’s domain. The blocking through domain name is already rendered ineffective as a result of this modification. If the primary adblockers recognize gtag.js as a javascript script, they will have trouble operating if the name of the javascript library is altered or if sites develop their own libraries.
uBlock Origin is successful against CNAME cloaking on Firefox, however, it is ineffective against Server-Side Tagging. What are the options for adblockers? The topic is not apparent; here are some suggestions, but I’m not sure they’ll work:
Using the URL parameters sent, automatically detect these “first party” calls to the “proxy” server. Except that these URL parameters vary from one site to the next, depending on the library used, the page saw, and other factors.
Block the execution of the javascript library that is responsible for calls to the “proxy” server. Except that you should detect not only the Google-provided javascript library but all javascript tracking libraries, including home libraries.
These proxy servers’ IP addresses should be blocked. Except for the fact that it will be necessary to manually locate and update the hundreds of IP addresses hidden behind these “proxy” servers… Alternatively, you might elect to restrict all Google App Engine IP addresses, potentially affecting a large number of applications. Having nothing to do with the tracking of anything. Not to mention the possibility that Google will decide to make the “proxy” server available to other hosts.
Never execute javascript in your browser, unless you have it heavily set, such as using the NoScript plugin. Effective option, although many websites will no longer function.
You can escape from personal data with utmost total opacity
Whereas many sites currently disclose your personal data outside your permission, it would still be feasible to audit the sites, verify the consent breach, and chronicle the exposures. The CNIL, for instance, might perform its job and penalise mistakes. With Server-Side Tagging, none of this is necessary; a site may now easily:
- Allow you to reply to a consent banner to provide the illusion of consent.
- While exposing your confidential information to a number of other parties without an external auditor seeing it (it will simply see the call “1st-party” to the server “proxy”, without knowing if the personal data is used, shared or sold behind).
Data in Google Cloud
The “proxy” server logs all queries it gets by default: App Engine logs information about every request it gets by default (for example, request route, query parameters, and so on).
However, the personal information contained in these requests is not the only information that Google obtains. Cookies connected with the domain of the site visited are delivered to the “proxy” server’s subdomain, similar to CNAME cloaking. Your session cookies will be transferred to Google’s cloud if they are connected with the site domain (rather than a distinct subdomain). This implies that the data stored on Google’s cloud is the user’s, not Google’s. We should still have confidence in Google.
Bypassing Adblockers and other browser protection – What is the USP?
As we’ve seen, Google doesn’t explain why a subdomain of the website was created for its “proxy” server:
The App Engine domain hosts the default server-side tagging implementation. Instead, we propose changing the deployment to utilise a subdomain of your website. It doesn’t require it; numerous publications have previously mentioned browser and adblocker protection bypasses as “benefits”:
- The importance of someone being able to avoid Safari’s limits regarding the duration of javascript cookies is highlighted in Simo Ahava’s article ” Server-side Tagging In Google Tag Manager “. To his credit, the author refuses to go into detail on how Server-Side Tagging allows users to avoid adblockers, instead stating that data collecting must take place after consent is obtained.
- ” GTM Server Side – Your Tagging’s Natural Evolution?” Adapted from Converteo. The benefits of being able to overcome browser limits such as those of Safari and Firefox, as well as adblockers, are listed in the article.
- From the Analytics crazy blog, “Introduction to Google Tag Manager Server-side Tagging.” Workarounds for browser and adblocker restrictions are also cited as an advantage.
- ” Is it good news that Google has introduced server-side tagging?” On the JDN, by Nicolas Jaimes. Because the article’s focus is on advertising, the bypassing of browser security features is presented as an advantage (although for the moment, the lack of third-party libraries means that Server-Side Tagging remains complex to implement).
Consequently, in addition to the performance, security, and control improvements, it’s a good bet that many sites will be lured to these “benefits.” For privacy activists, the inability to inspect websites will be a significant setback. We hope that browsers and adblockers work out a solution so that privacy-conscious Internet users may continue to protect themselves.



{kind=link}